데이터 마이닝(data mining)은 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아 내는 것이다. 다른 말로는 KDD(데이터베이스 속의 지식 발견, knowledge-discovery in databases)라고도 일컫는다.
데이터 마이닝은 통계학에서 패턴 인식에 이르는 다양한 계량 기법을 사용한다. 데이터 마이닝 기법은 통계학쪽에서 발전한 탐색적자료분석, 가설 검정, 다변량 분석, 시계열 분석, 일반선형모형 등의 방법론과 데이터베이스 쪽에서 발전한 OLAP (온라인 분석 처리:On-Line Analytic Processing), 인공지능 진영에서 발전한 SOM, 신경망, 전문가 시스템 등의 기술적인 방법론이 쓰인다.
데이터 마이닝의 응용 분야로 신용평점 시스템(Credit Scoring System)의 신용평가모형 개발, 사기탐지시스템(Fraud Detection System), 장바구니 분석(Market Basket Analysis), 최적 포트폴리오 구축과 같이 다양한 산업 분야에서 광범위하게 사용되고 있다.
단점으로는, 자료에 의존하여 현상을 해석하고 개선하려고 하기 때문에 자료가 현실을 충분히 반영하지 못한 상태에서 정보를 추출한 모형을 개발할 경우 잘못된 모형을 구축하는 오류를 범할 수가 있다.
데이터마이닝은 데이터 분석을 통해 아래와 같은 분야에 적용하여 결과를 도출할 수 있다.
분류(Classification): 일정한 집단에 대한 특정 정의를 통해 분류 및 구분을 추론한다 (예: 경쟁자에게로 이탈한 고객)
군집화(Clustering): 구체적인 특성을 공유하는 군집을 찾는다. 군집화는 미리 정의된 특성에 대한 정보를 가지지 않는다는 점에서 분류와 다르다 (예 : 유사 행동 집단의 구분)
연관성(Association): 동시에 발생한 사건간의 관계를 정의한다. (예: 장바구니안의 동시에 들어 가는 상품들의 관계 규명)
연속성(Sequencing): 특정 기간에 걸쳐 발생하는 관계를 규명한다. 기간의 특성을 제외하면 연관성 분석과 유사하다 (예: 슈퍼마켓과 금융상품 사용에 대한 반복 방문)
예측(Forecasting): 대용량 데이터집합내의 패턴을 기반으로 미래를 예측한다 (예: 수요예측)

출처 : https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0_%EB%A7%88%EC%9D%B4%EB%8B%9D
http://www.dbguide.net/knowledge.db?cmd=view&boardUid=177566
분류(Classification): 일정한 집단에 대한 특정 정의를 통해 분류 및 구분을 추론한다
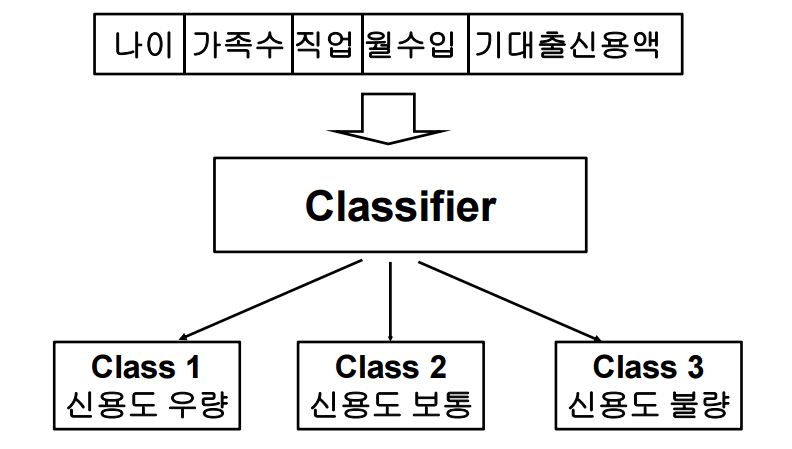
그림 1. 신용도 분류
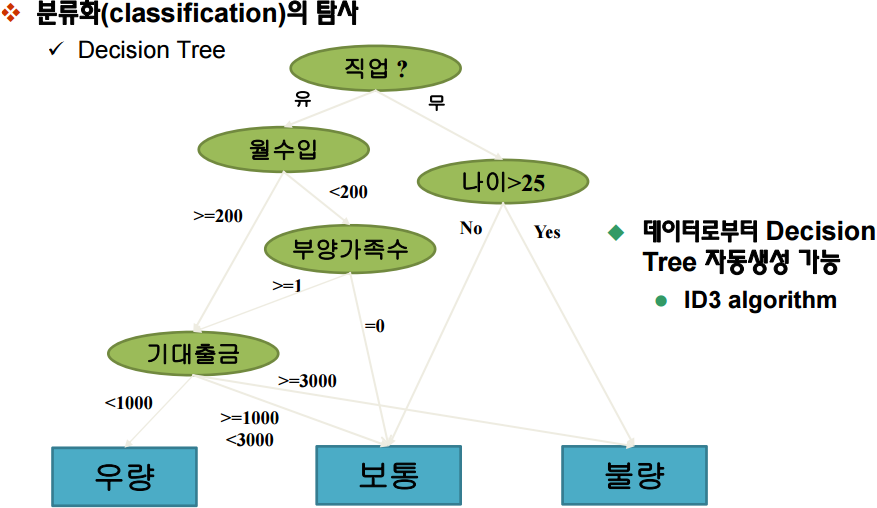
그림 2. 분류화 로직
출처 : http://www.slideshare.net/kwnam4u/01-41434457?from_action=save
모형의 평가
하나의 자료 분석시 여러가지 가능한 모형을 적합시키게 되는데 이중 최적의 모형 을 선택하기 위해 필요
모형의 평가 방법 – 예측력: 얼마나 잘 예측하는가 ? – 해석력: 모형이 입력/출력 변수간의 관계를 잘 설명하는가 ? – 효율성: 얼마나 적은 수의 입력변수로 모형을 구축했는가 ? – 안정성: 모집단의 다른 자료에 적용했을 때 같은 결과를 주는가 ?
모형의 평가: 어떤 모형이 랜덤하게 예측하는 모형보다 예측력이 우수한지, 그리 고 고려된 모형들 중 어느 모형이 가장 좋은 예측력을 보유하고 있는지를 비교 / 분석
출처 : http://datamining.dongguk.ac.kr/lectures/2011-1/dm/dm_notes_v0.5.pdf
의사결정트리(Decision Tree)


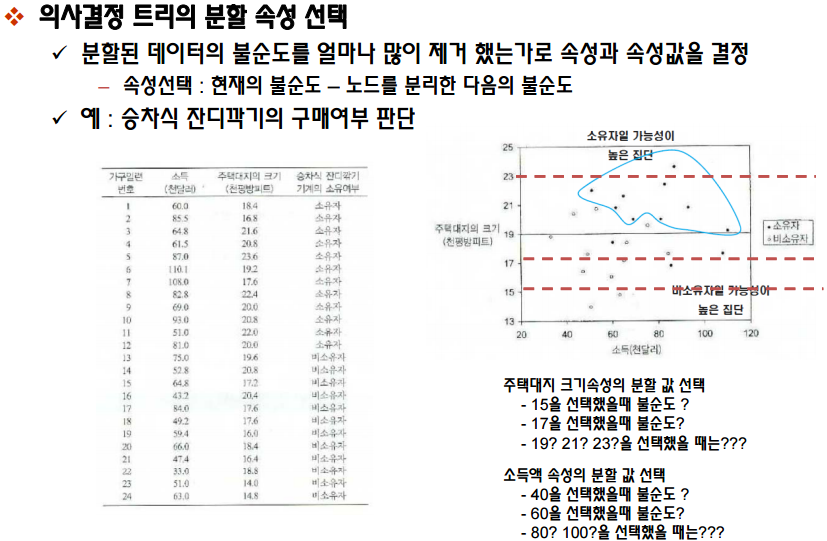
출처 : http://www.slideshare.net/kwnam4u/0601-41434770
http://datamining.dongguk.ac.kr/lectures/2011-1/dm/dm_notes_v0.5.pdf
연관성분석
데이터 안에 존재하는 항목간의 연관규칙 (association rule)을 발견하는 과정
연관규칙: 상품을 구매하거나 서비스를 받는 등의 일련의 거래나 사건들의 연관성 에 대한 규칙
연관성 분석을 마케팅에서 손님의 장바구니에 들어있는 품목간의 관계를 알아본다 는 의미에서 장바구니분석 (market basket analysis)이라고도 함
왜 연관성 분석을 하는가 ?
고객의 슈퍼마켓에서 구입한 물건들이 담겨져 있는 장바구니의 정보를 생각해보자.
연관성 분석은, 특정한 상품을 구입한 고객이 어떤 부류에 속하는지, 그들이 왜 그 런 구매를 했는지 알기 위해서 고객들이 구매한 상품에 대한 자료를 분석하는 것
이러한 분석을 통하여 효율적인 매장진열, 패키지 상품의 개발, 교차판매전략 구 사, 기획상품의 결정 등에 응용할 수 있음
연관성 분석의 응용
백화점이나 호텔에서 고객들이 다음에 원하는 서비스를 미리 알 수 있음
신용카드, 대출 등의 은행서비스 내역으로부터 특정한 서비스를 받을 가능성이 높 은 고객의 탐지 가능
입력층: 각 입력변수에 대응되는 노드로 구성. 노드의 수는 입력변수의 개수와 같 음
의료보험금이나 상해보험금 청구에서 특이한 형태를 보이는 경우 보험사기의 징조 가 될 수 있고 추가적인 조사 필요
환자의 의무기록에서 여러 치료가 같이 이루어진 경우 합병증 발생의 징후 탐지
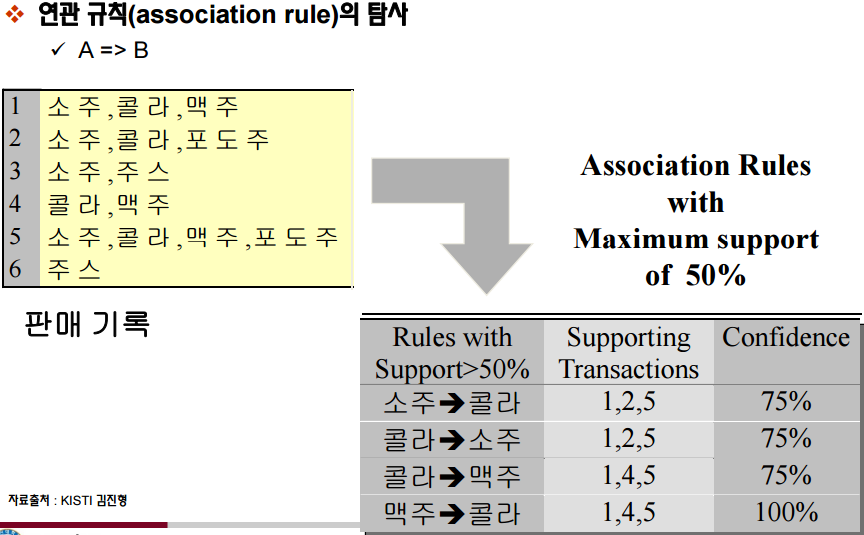
출처 : http://datamining.dongguk.ac.kr/lectures/2011-1/dm/dm_notes_v0.5.pdf
http://www.slideshare.net/kwnam4u/01-41434457?from_action=save
http://daddycat.blogspot.kr/2011/06/blog-post_6849.html
추천시스템
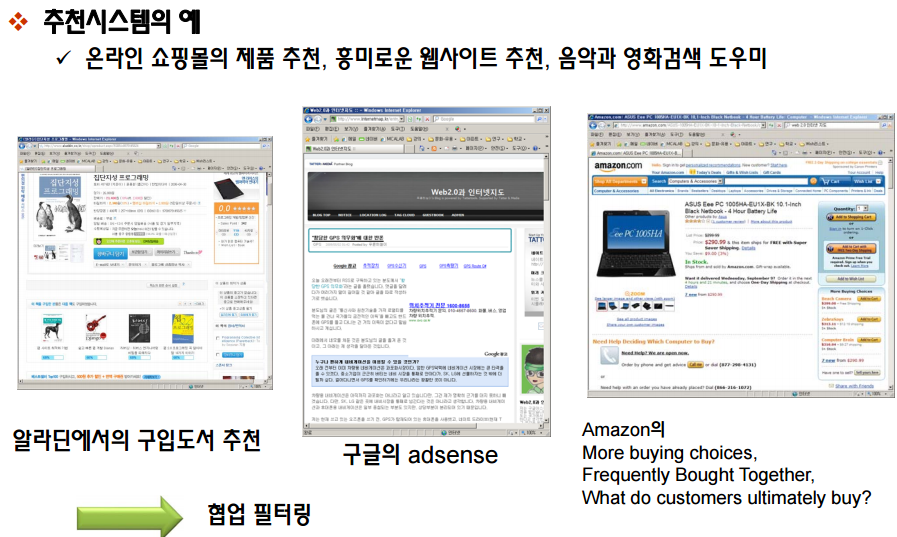
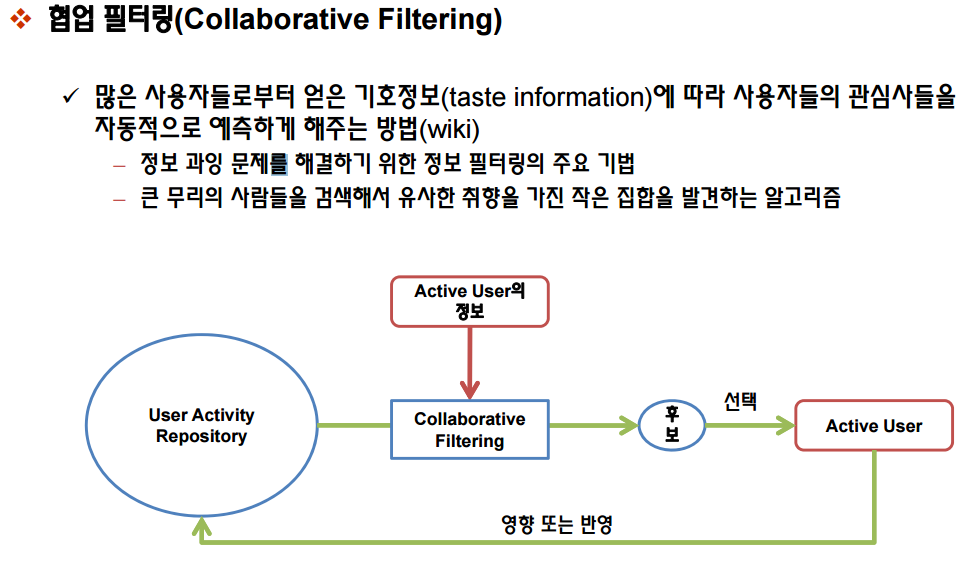

출처 : http://www.slideshare.net/kwnam4u/02-41434707?related=1
데이터 마이닝 입문할때 이 PDF로 하면 좋을거 같다 찾아보니 경북대 대학원 교재 인거같음…
http://datamining.dongguk.ac.kr/lectures/2011-1/dm/dm_notes_v0.5.pdf